给自己一个 高薪 高逼格 的未来 - IT人才
(以下数据来自Jobshow)
0基础学习? 初中高学历?
课程分级教学,总有适合你的课程
我是0基础
4-6个月成为IT工程师
初、高中毕业生
量身定制课程体系
本、专科毕业生
实训5个月
具备2年工作经验

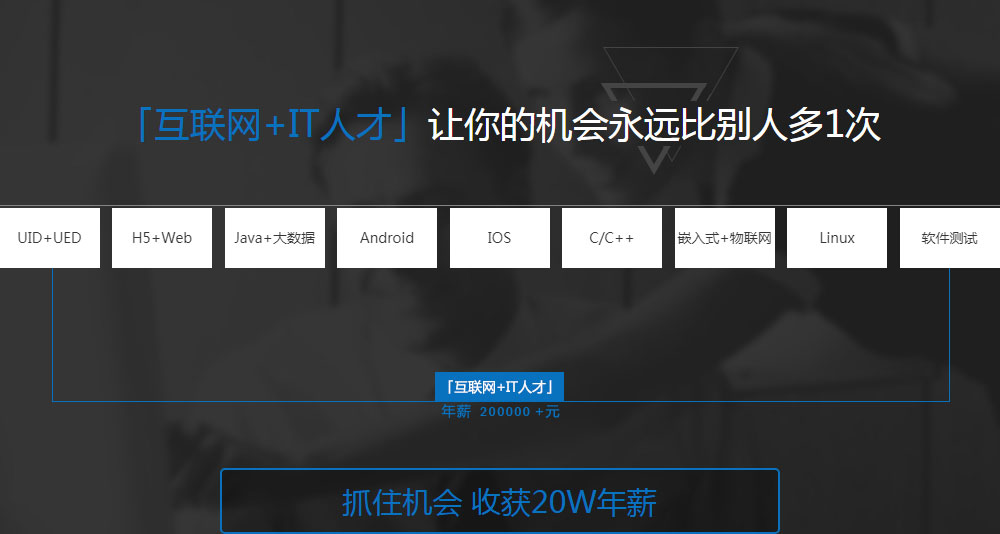
「互联网+IT人才」的T型人才
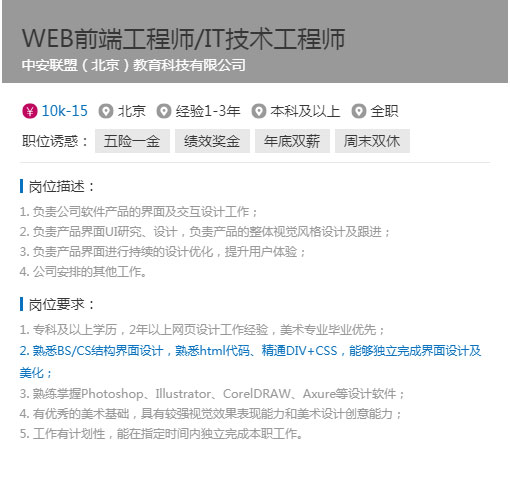
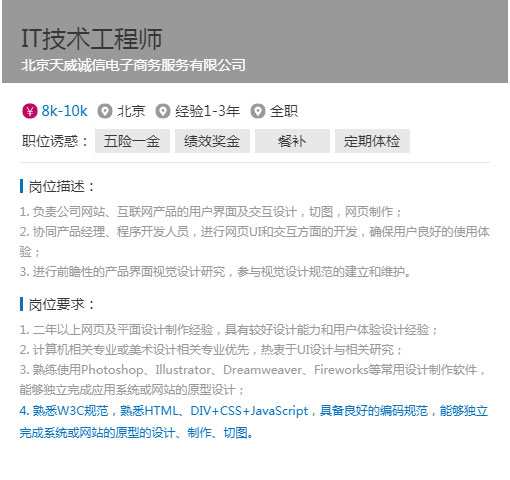

以就业为导向,从企业实际需求出发
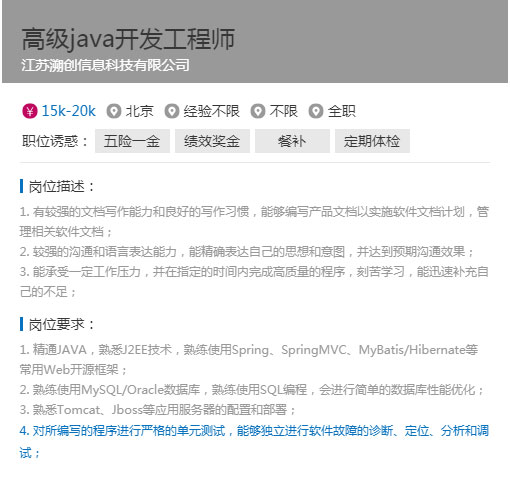
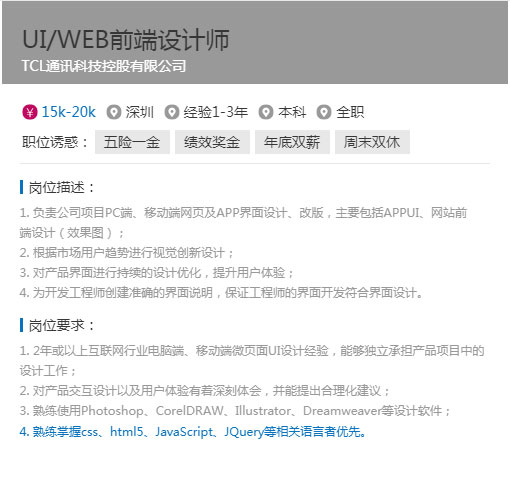
市场需求巨大的岗位



















超过20000人获得了镀金池职业规划方案

学员关心的问题
你是否有,这样的困惑?
1、自己适合学吗?
2、学不会怎么办?
3、学完能进哪些企业?
4、学完能挣多少钱?
5、学费多少钱?
6、不知道学什么课程?






我们为您 精挑细选「互联网+IT人才」课程体系

众多名校 保驾护航
众多学员在这里重新开启人生 我要改变











国内IT企业任你选 进入500强
这些企业里面都有你的学长 我要加入
中国联通
华为
惠普
IBM
富士通
亚马逊
用友
淘宝网
新浪
亚信联创
电讯盈科
百度
腾讯
阿里巴巴
58同城
迅雷
微软
搜狐
甲骨文
东软
软通动力
四达时代
你的明天会比他们更美好